%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Visual Model

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Fresh Picks
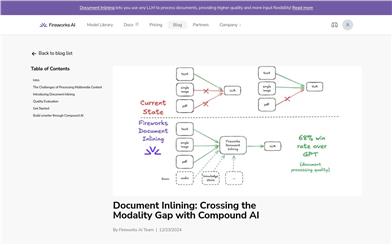
Document Inlining
Document Inlining is a composite AI system launched by Fireworks AI that transforms any large language model (LLM) into a visual model to handle images or PDF documents. This technology utilizes automated processes to convert any digital asset format into an LLM-compatible format, enabling logical reasoning. Document Inlining parses images and PDFs directly into the chosen LLM, offering improved quality, input flexibility, and an exceptionally simple user experience. It addresses the limitations of traditional LLMs when handling non-text data by breaking tasks down into specialized components, enhancing the quality of textual model reasoning while simplifying the developer experience.
AI Model
51.6K
Internvit 6B 448px V2 5
InternViT-6B-448px-V2_5 is a visual model built upon InternViT-6B-448px-V1-5, which enhances the visual encoder's ability to extract visual features by utilizing ViT incremental learning and NTP loss (Stage 1.5). It particularly excels in domains where representation is lacking in large-scale network datasets, such as multilingual OCR data and mathematical charts. This model is part of the InternVL 2.5 series, maintaining the same 'ViT-MLP-LLM' architecture as its predecessor, while integrating the newly incrementally pretrained InternViT alongside various pretrained LLMs, including InternLM 2.5 and Qwen 2.5, utilizing a randomly initialized MLP projector.
AI Model
53.0K
Fresh Picks

Sapiens
The Sapiens visual model, developed by Meta Reality Labs, focuses on handling human visual tasks, including 2D pose estimation, body part segmentation, depth estimation, and surface normal prediction. It has been trained on over 300 million human images, showcasing high-resolution image processing capabilities and excellent performance even in data-scarce conditions. Its straightforward design facilitates scalability, and its performance significantly improves with increased parameters, surpassing existing baseline models in multiple tests.
AI image generation
50.0K
Longva
LongVA is a long context transformer model capable of processing over 2000 frames or 200K visual tokens. It achieves leading performance in Video-MME among 7B models. The model is tested on CUDA 11.8 and A100-SXM-80G and can be quickly deployed and used through the Hugging Face platform.
AI Model
48.9K
Florence 2 Base
Florence-2, a high-performance visual foundation model developed by Microsoft, utilizes a prompt-based approach to handle a wide range of visual and vision-language tasks. The model can interpret simple text prompts to perform tasks like description, object detection, and segmentation. It is trained on the FLD-5B dataset, which consists of 540 million images with 5.4 billion annotations, mastering multi-task learning. Its sequence-to-sequence architecture enables strong performance in both zero-shot and fine-tuning settings, establishing it as a competitive visual foundation model.
AI Image Generation
63.2K
Florence 2 Large
Florence-2-large, developed by Microsoft, is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of visual and visual-language tasks. The model can interpret simple text prompts to perform tasks such as image description, object detection, and segmentation. It is trained on the FLD-5B dataset, which contains 540 million images with 5.4 billion annotations, making it proficient in multi-task learning. Its sequence-to-sequence architecture enables it to perform well in both zero-shot and fine-tuning settings, proving to be a competitive vision foundation model.
AI image generation
57.1K
Llama3v
llama3v is a state-of-the-art (SOTA) visual model based on Llama3 8B and siglip-so400m. It is an open-source VLLM (Visual Language Multi-Modal Learning Model) with model weights available on Huggingface, supporting fast local inference, and released inference code. This model combines image recognition and text generation by adding a projection layer to map image features to the LLaMA embedding space, enhancing its understanding of images.
AI Model
66.0K
Page Assist A Web UI For Local AI Models
Page Assist is a convenient web user interface that simplifies interaction with your local AI models. You can use it to interact with your local AI models within your browser, or as a web user interface for local AI model providers like Ollama Repo. Current features include sidebar task support, visual model support, a minimized local AI model web interface, internet search functionality, a sidebar PDF dialogue box, and document chat (PDF, CSV, TXT, MD formats).
AI Development Assistants
116.2K

Vmamba
VMamba is a visual state-space model that combines the advantages of convolutional neural networks (CNNs) and visual Transformers (ViTs), achieving linear complexity without sacrificing global perception. It introduces the Cross-Scan Module (CSM) to address the issue of direction sensitivity and can demonstrate excellent performance in various visual perception tasks. As the image resolution increases, it shows more significant advantages compared to existing benchmark models.
AI Model
58.0K

AIM
This paper introduces AIM, a family of visual models pre-trained using autoregressive objectives. Inspired by their textual counterparts, the large language models (LLMs), these models exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of visual features improves with increasing model capacity and dataset size, and (2) the value of the objective function correlates with model performance on downstream tasks. By pre-training a 70-billion parameter AIM on 2 billion images, we achieved 84.0% accuracy on ImageNet-1k using a frozen backbone. Interestingly, even at this scale, we observe no signs of performance saturation, suggesting that AIM may represent a new frontier in training large-scale visual models. AIM's pre-training is similar to that of LLMs and does not require any image-specific strategies to stabilize large-scale training.
AI Model
60.2K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K
Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M